Reflections on AI
Attention is All You Need
May 27, 2023 Source
Well, this is it: the famous paper from researchers at Google who introduced the “Transformer” architecture. My understanding is that this architecture forms the basis for modern large language models including:
I won’t lie and pretend most of this paper wasn’t over my head. But hey, at least I definitely read it!
Probably the best way that I can summarize the paper is by providing my seriously dumbed-down version of how I understand it to have been a paradigm-shifting moment in AI research and why it was so influential. I’ll also share some random things I learned while reading this paper, with some major assistance from ChatGPT.
Probably the best place to start is this very cool visualization of an “Evolutionary Tree” of large language models from user Mooler0410 on GitHub:
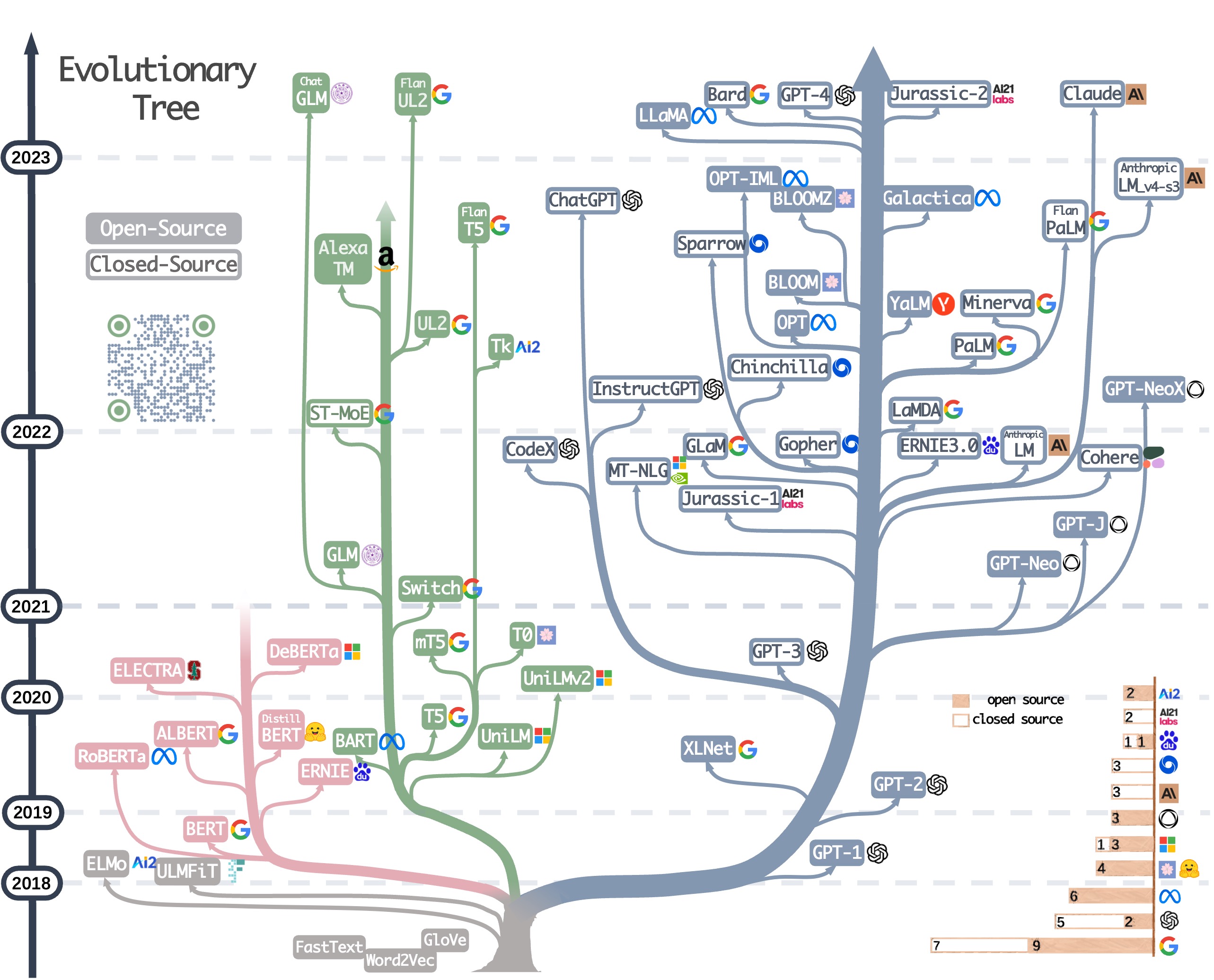
My understanding (if I’m wrong, I am sure someone will correct me before long!) is that the big blue branch on the right is the lineage of transformers, with the other colors representing fundamentally different architectures, mostly falling within the broad category of encoder-decoder systems.
Fundamentally, all of these systems process input strings, like The five boxing
wizards jump quickly. Encoder-decoder systems handle this task in a linear
fashion: they read the string from the beginning to the end, maintaining some
state along the way. The encoder component (which will inevitably comprise
many subcomponents) is responsible for taking the input data and storing some
internal representation of it; and the decoder component uses that internal
representation to ultimately produce some output.
So far, so good. This sounds very familiar to me to, for example, how compilers work in the world of computer software: first text from a file is parsed into tokens, those tokens are organized into a syntax tree, and then the tree is used to produce output in the form of a lower-level language such as bytecode or assembly. (Importantly, the syntax tree could also be translated back into a different higher-level programming language, assuming all of the same or equivalent semantic constructs are available; e.g. you could produce the same program in C, Java, JavaScript, Python, Ruby, etc. from a simple-enough AST).
A significant limitation of this architecture is that the system must process input serially, which poses at least two challenges:
- The process cannot be parallelized. This alone is a huge issue as it limits a system’s potential to scale to support very large data sets. (The old saying from Brooks’s law comes to mind: “nine women can’t make a baby in one month”.)
- These systems struggle with long-range dependencies, i.e. relationships between tokens that are far apart in the input string.
Multiple approaches to improve the performance of encoder-decoder systems had been invented over the past few decades, including recurrent neural networks (RNNs) which build a sort of “memory” by looping back through earlier parts of a sequence while progressing through it; and long short-term memory (LSTM) networks, which utilize a specialized component that selectively remembers or chooses to forget pieces of information as a sequence is processed. None of these approaches provided a solution to the parallelization problem; and each came with their own drawbacks.
The key innovation of transformers was to do away with the encoder-decoder paradigm (hence the title “Attention is all you need”, as in: You don’t need separate encoding and decoding steps). The Transformer architecture involves a system of relating every token in an input string to every other token in the string. This is surely an over-simplification; but the way I think about this is that even if a string is 1,000 tokens (words) long, the very last token may have just as much relevance to the meaning of the 1st token as to the 999th token.
“Attention” refers to the mechanism by which relationships between tokens are evaluated by the system. The term “self-attention” describes the new mechanism introduced in the paper whereby this mechanism is applied on the input string itself during parallel processing, whereas previous architectures used attention to produce output on a compressed representation of the input data—out of necessity, since lack of parallelization posed practical limits on how much data could be processed at once.
Approaching the problem this way allows for transformers to be parallelized to an arbitrary degree: every single token in an input string could theoretically be processed in parallel, because it is not necessary to read the sequence from beginning to end. Furthermore it resolves the problem from previous encoder-decoder systems of failing to capture relationships between tokens that are far apart.
If I may, this really reminds me of the film Arrival, in which human scientists struggle to decipher an alien language whose written form consists of circular ink blots.
Without spoiling the movie (highly recommended if you haven’t already seen it!), the idea that this language is circular turns out to be significant to the plot. It is related to how the aliens perceive reality and their awareness of connections that humans might be unable to observe. The notion that the symbols we use to represent our world form our cognitive building blocks is a fascinating one and truly one of the most novel sci-fi ideas I have seen produced by a major film studio in years.
But back to the Google paper! I have just a few more thoughts to share; then I will wrap this up.
I was intrigued to learn that one of the ways the researchers evaluated the performance of the Transformer architecture is with something called a “BLEU score”. This stands for “bilingual evaluation understudy” and is a score used to evaluate machine translation performance, i.e. how well a system is able to translate text from one language to another.
Basically the way it works is that for a given pair of languages, e.g. German and English, there is a large set of phrases, each with a corresponding set of “reference translations” from actual human translators. These phrases are given to the machine translation system to translate, its output is compared to the reference translations, and the system is scored based on its output’s similarity to the reference translations. This score is the BLEU score.
A score of 100 would mean that the system’s output exactly matched a reference translation for every piece of text in the input set. Presumably if the system output complete randomness it would get a score very close to 0.
This score is very curious to me. It doesn’t seem like a great way of assessing the performance of a translator, although I recognize it isn’t meaningless, and I also admit I can’t really come up with a better way. I asked ChatGPT if we know what human translators score on similar tests, and after leading with a bunch of caveats about how this depends on many factors etc. it told me that skilled translators have been known to score in the 40ish range.
Something else I found fascinating while reading this paper, which isn’t about the paper per se but rather about my ongoing conversation with ChatGPT while I read it, is that there is a very distinct impediment to really explaining how LLMs work or what attention means, precisely, due to the automated nature of how weights are calculated and what they mean. Here are just a few excerpted examples of how ChatGPT attempted to explain things to me during my session:
Regarding query, key, and value vectors:
While it may be difficult to interpret the precise meaning of these vectors, they help the model to encode and process the relevant contextual information required for each token
Regarding the meaning of each dimension of a vector (up to 768!):
it’s difficult to interpret the precise meaning of individual dimensions
Regarding an example that ChatGPT provided to make the idea of vectors concrete:
The simplified values in the example are not interpretable
And putting it all together:
These high-dimensional vectors (e.g., 768 dimensions in BERT-base) enable the model to encode and process a large amount of information, but their internal structure and meaning may not be easily interpretable by humans.
These quotes provide a strong flavor of what Yudkowsky fears when he talks about inscrutable matrices.
Is this the final chapter, then? Will transformers get us all the way to superhuman general intelligence? Sam Altman (CEO of OpenAI) doesn’t think so: while they undoubtedly changed the game of AI research, Altman believes there are architectural advances yet to be discovered that we will need to find before AI systems are able to exceed human ability on all cognitive tasks.
So maybe attention isn’t all you need.